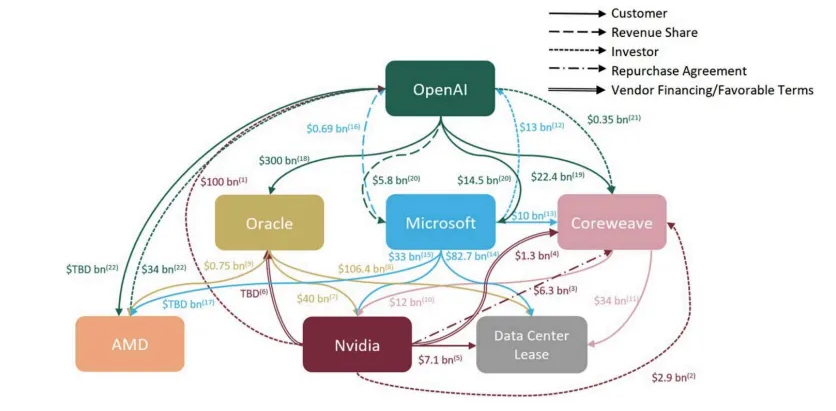
Mega Funds at Seed: Existential Risk or Smart Beta Opportunity?
December 18, 2025
Most of our code at Level is in python. We have a fairly modern stack that includes excellent tools like ruff and pre-commit. However, our most vexing task is dependency management and so one of our most important tools is python poetry. As a part of rolling out poetry for dependency management, we also put together a full container lifecycle to carefully manage our execution environments; the main issue we had—until now—is that this container build process was very slow both because of the number of packages and the size of some of them (ahem pytorch ahem).
As a primer: let’s imagine we’re writing a new function that downloads a file from the National Science Foundation, computes some properties about that data, and then uploads the results to our Level Frame system. We do this type of thing constantly! Let’s say that the file is a CSV; we could manually write code to parse this CSV and extract statistics, but instead, it makes much more sense to simply use pandas, since it’s a very stable open-source library that does exactly that. (We don’t want to re-invent the wheel.)
So, how do we go about actually using this library? We have a few options here:
pip or something like that.condas and distribute pre-built environments.The fastest thing is option number 1, but this solution doesn’t scale particularly well. When we import a package, it can have its own dependencies, so we would need to manually import all of its own dependencies. Pretty soon, we’re managing literally hundreds of dependencies by hand and we haven’t even addressed upgrades. Also, for those of you who laughed at the idea of downloading the source code and just including it in our codebase, there is one small open-source package that is not actively maintained and we actually did inline it! Sometimes, the simplest solution just works.
The second solution becomes a problem when we want the code we developed locally to run in the cloud. We used to use this strategy sometimes, especially when working on certain research projects. It’s useful when writing one-off notebooks, but now we’ve entirely moved away from this approach.
We don’t like conda very much because it breaks our mental model on repository-level isolation. Yes, there are ways to properly set up conda and many very respected python shops use it. We ultimately settled on poetry, which manages packages and virtual environments for us. It took a bit of configuring, but we have an ergonomic setup that works for our purposes. We’ve also started to contribute back to poetry and we are hoping to give back to the open-source projects that we love.
With poetry, we have a standard pyproject.toml file that declares all of our dependencies. We can run poetry install to quickly spin up an environment that has all of the dependencies that we need to run our code. We also use dependency groups and optionals because of the fact that …
We love pytorch, but it is enormous and very slow to install. Almost exclusively because of this library, we have a whole way of managing what we call environment variants. In a nutshell: we have different groups of packages based on different execution contexts. We still require that all of our packages are cross-compatible with each other, even if they are not necessarily used in the same variant; this design decision works well with poetry and reduces many complexities.
For example, we have a base variant that includes things like numpy. That means that any time we run code, we know that we have it available to use. However, we also use poetry‘s dependency group feature to install dev dependencies, which are packages that are only needed when actively writing code, as opposed to just executing the code in, say, AWS. For example, we have ruff in our dev dependencies, which is a static analyzer to catch bugs; when actually running the code, you would never need it, so we can safely skip installing it when running things on AWS.
One of our most important variants is the ml variants, which installs things like pytorch. Again, we ensure that everything in the ml variant is compatible with both our base variant and dev variant: you can’t, for example, install one version of numpy in the base variant and another version in the ml variant. This variant is implemented through poetry optionals, and we declare the package like this:
[tool.poetry.dependencies]
torch = { version = "^2.1.1", optional = true }
[tool.poetry.extras]
ml = ["torch"]In this way, we can guarantee that there are no dependency conflicts, but we can also install different sets of packages depending on the type of code that we’re actually going to run.
The last piece of all this is our docker-based container system. Most of our code runs on AWS in ECS, so we build containers that capture all of our dependencies and we then spin up jobs on them. Since we use Github to manage our code anyways, we use Github actions to run the docker container building process.
Originally, our container build process took five or six minutes to run for the base image and about 21 minutes for our ml image, which is just too long. When working on a feature, if we wanted to run something on ECS, there would be a huge delay between writing code and waiting for the container to become available to test in AWS.
We decided to rethink our container build process from scratch. The solution we settled upon was hashing and caching. What does that mean? Well, poetry builds something called a poetry.lock file that contains exact versions of which packages we’ve installed. Because of this system, we generate canonical hashes of our container variants as so:
poetry, we generate the full dependency tree for each variant. For example, if we were to select the ml variant, poetry can tell us the full set of packages that would need to be installed, included any level of recursive sub-dependencies.poetry, we then figure out exactly which package version is installed. Although this step is relatively straightforward, we have to handle oddball things like package versions for packages declared as git-based dependencies.Using this system, every time we commit code, we can tell if the hash for any variant has shifted. We now tag containers based on their respective canonical hashes and, if a hash doesn’t change, we know that we don’t have to rebuild the container. When developing, as long as no dependencies change, containers are built and available to us within 20 seconds.
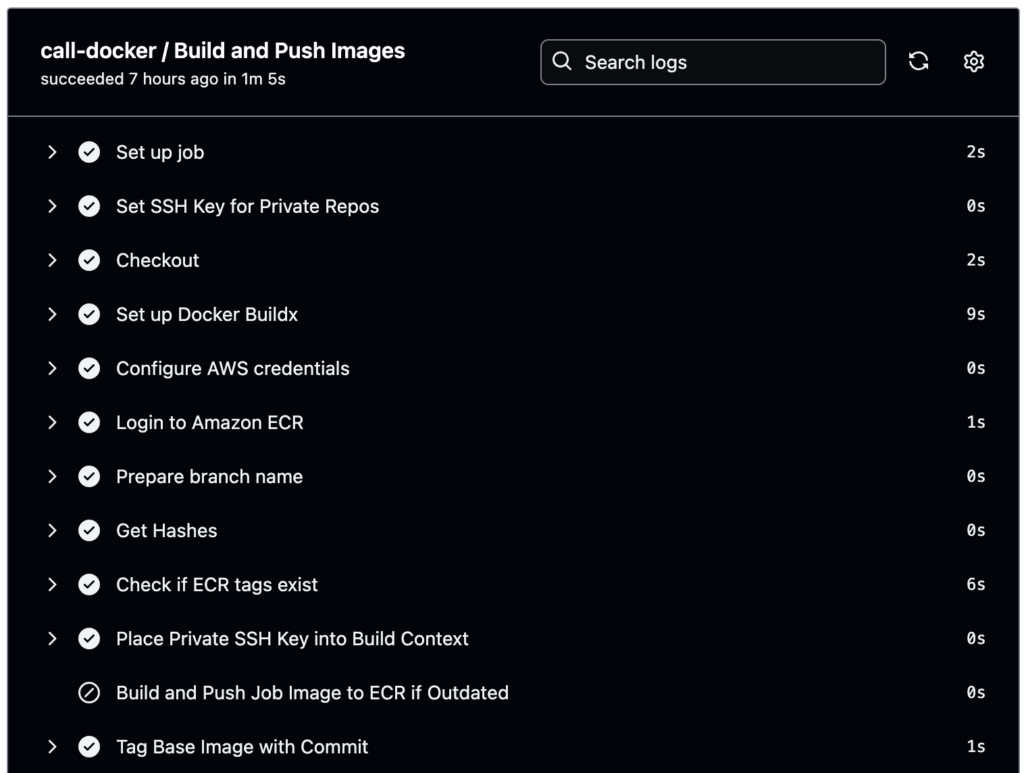
One last consideration: what happens if we’re testing a new dependency? Now, we could simply change our pyproject.toml file and include this new dependency. We would have to wait for the container to be re-built from scratch—ugh!—which may be annoying if we are quickly iterating on a feature. We have a special dependency group called exp that does not trigger a re-build; instead, those dependencies are installed on the fly when ECS being execution. We don’t let exp dependencies land on our main branch, but it’s a nice ergonomic pattern when quickly testing new libraries.
Although there are some technical details we’ve glossed over (like getting our code on the container, pre-commit hooks to ensure hashes stay properly synchronized, and manual cache invalidation for when things end up in an inconsistent state), the bulk of the details of our process are outlined in this post. For what it’s worth, we also have more intelligently written our Dockerfiles and done some systems magic so our base container builds only take three minutes anyways and we are working on finding other optimizations. Our new dependency management and container build process has helped us test things much faster and we’re excited to continue to improve it!