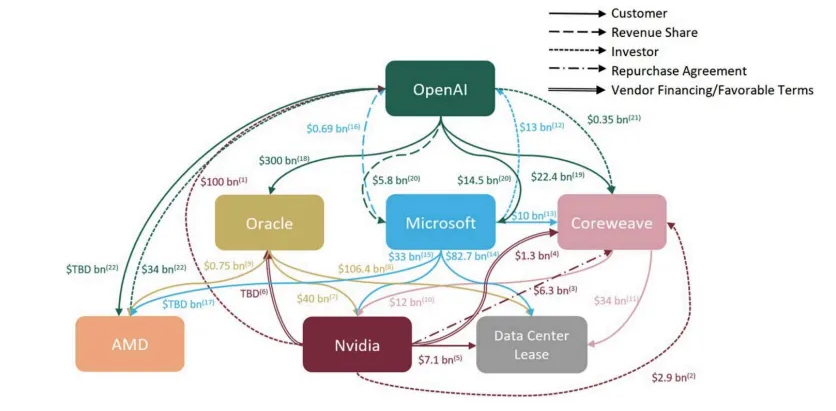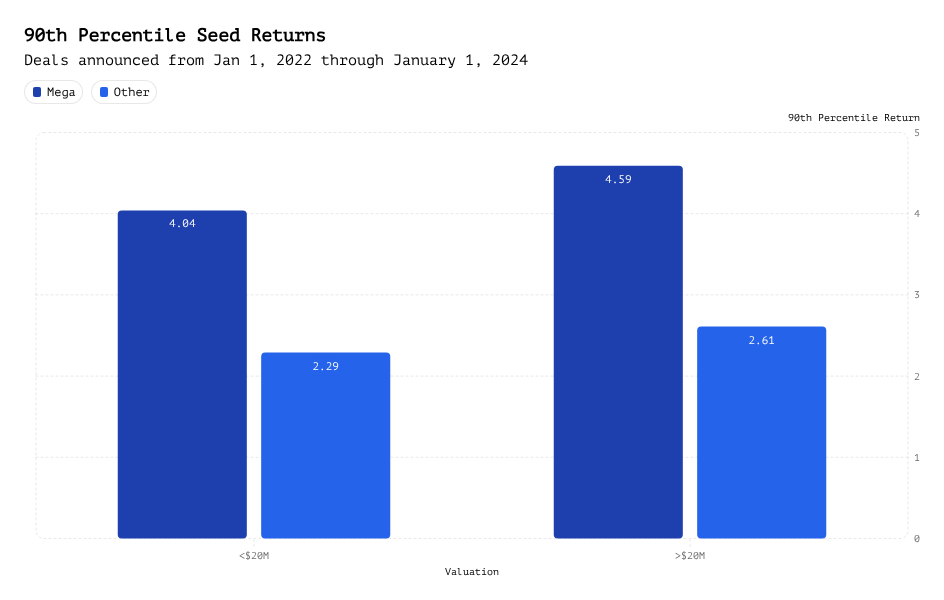
Mega Funds at Seed: Existential Risk or Smart Beta Opportunity?
December 18, 2025
We have about 500k source lines of code that implement all of our research engineering. We execute code in a variety of contexts, whether ephemeral lambdas, beefy EC2 instances with GPUs, or our laptops when developing code. Although we have somewhat traditional change control management for our code, we also have a central system that handles our configuration, no matter the execution context. Our RFC 5 describes this process and we thought we’d share some of the insights we’ve learned here.
Configuration is a somewhat “I’ll know it when I see” it generally refers to a set of important key–value pairs. For example, we use configuration to store:
DEBUG or INFO)Configuration tends to be important values that cut across the codebase that change between execution contexts (e.g. a laptop vs. AWS), but never within an execution context, i.e., once code starts running, we do not allow for configuration values to change.
In this way, we can ensure that—even across long-lived processes—all parts of our codebase have a consistent set of configurable values to read from. Notably, configuration is linked to the concept of environment variables. Many services and processes read variables from the current process environment, which gives rise to consistent patterns like seeing ENV=PROD for a production environment. While our configuration system interoperates with environment variables, we have designed a more consistent interface to these settings.
In order to maintain our system, we have a few rules with configuration. Namely, we require configuration to take on basic values with well-defined types, we forbid real-time configuration value changes, and we also enforce that configuration is the first code that executes in any code. That way, we can ensure that configuration is the root of all our code and we can rely on these values existing before doing anything else.
We currently have five sources of configuration, in priority order:
.lvc.env file: we respect a special environment file that we read in the current working directory.These configuration sources have a very consistent naming scheme that is enforced by our code. For example, if we want to declare an Airtable API token, we can easily declare this with proper typing. By giving the field an alias of airtable_api_key, we are asking our system to synchronize this value in code with the environment variable AIRTABLE_API_KEY (case-insensitive), which is an environment variable understood by other systems. Furthermore, we declare documentation, which gets automatically parsed by our toolchain. Finally, note that we use a double underscore __ in names as a special convention to synchronize with AWS Secrets Manager.
airtable__token: SecretStr = Field(default=SecretStr(""), alias="airtable_api_key")
"""
The Airtable token to use for Airtable operations.
"""One additional feature of our system is that we first interpret the value of ENV, which is a specially handled configuration value that decides if we are in develop, staging, or production. Based on this value, we actually load in different configuration values from AWS. We currently use the canonical convention of prod/some/value and dev/some/value in naming secrets in AWS Secrets Manager. For example, the aforementioned Airtable token would be matched with prod/airtable/token or dev/airtable/token depending on the value of ENV. In this way, we can ensure that resources are not mixed across environments, while keeping the interface in code very simply: code paths just need to use the value of airtable__token without worrying about which environment they are in.
We currently use a combination of pydantic and our own custom code to implement our configuration system. Because our configuration system is the literal core of our code (it’s import location is core.), our entire toolchain understands configuration. We have thus been able to implement several easy features as a result:
Annotated[SecretStr, RandomRotation()]) and our CI/CD system automatically deploys rotations.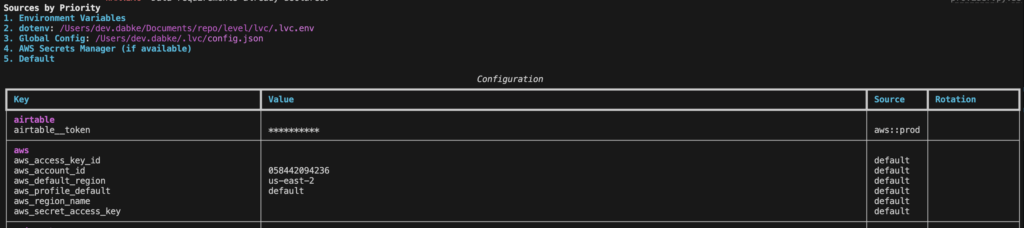
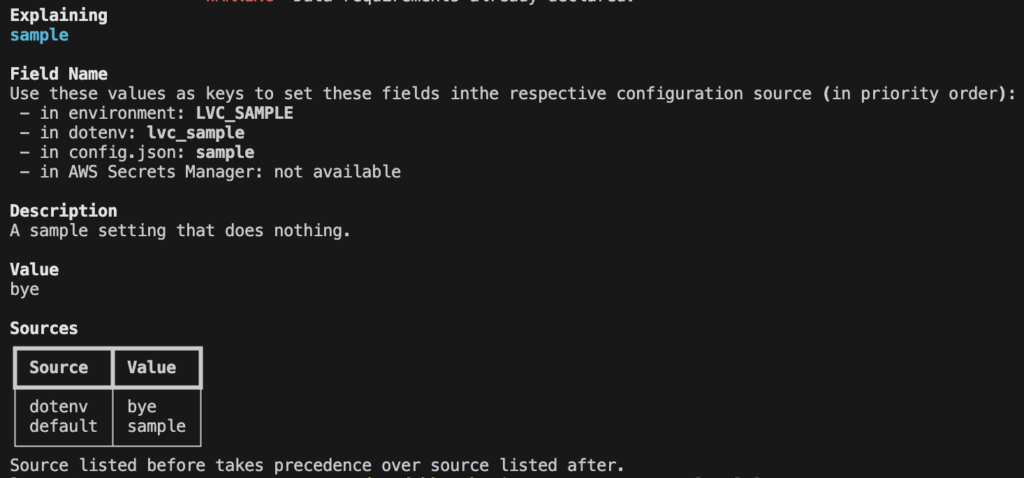


One of the biggest benefits of our central configuration system is increase security. We can avoid hard-coded credentials, non-secure credential sharing (e.g. sending over plaintext in slack), and other common pitfalls. If we update a secret value, all of our code immediately gets access to this value without having to manually update our many systems. Even our code has security provisions: we use the specialized SecretStr construct, which in code, prints out as * instead of the real value. That way, we know that our logs are properly sanitized of any potentially sensitive information.