Mega Funds at Seed: Existential Risk or Smart Beta Opportunity?
December 18, 2025
At Level, we continually train our deep learning models. In addition to training every week with new data, we also experiment with new architectures, deploy hyperparameter sweeps, and recompute Jackknife+ folds. To do all this, we need GPUs and they need to go brrr.
Our orchestration tool of choice to support our ETL processes is Prefect, which is both a Python framework to build workflows and a corresponding cloud-based platform to help manage them. We built a custom abstraction over Prefect that makes our engineering experience as minimal as possible while leveraging Prefect’s ability to launch custom compute per workflow. To create a workflow that runs on AWS GPUs, we need only write the following code:
from lvc.flow.builder import AwsEcsImage, AwsEcsMachine, Workflow
workflow = Workflow(
machine=AwsEcsMachine(
is_gpu=True,
storage=50,
cpu_value=2048,
memory_value=4096,
image=AwsEcsImage.ml,
),
)That simple declaration of an AwsEcsMachine hides the details of a variety of systems that all interact with each other. When someone lands a new commit on our main branch with code like above, our CI/CD system:
AwsEcsImage.ml specifies to our system).git commit hash).Once a deployment is in Prefect Cloud, we can see it available to us in the UI, with out-of-the-box metrics and current run information:
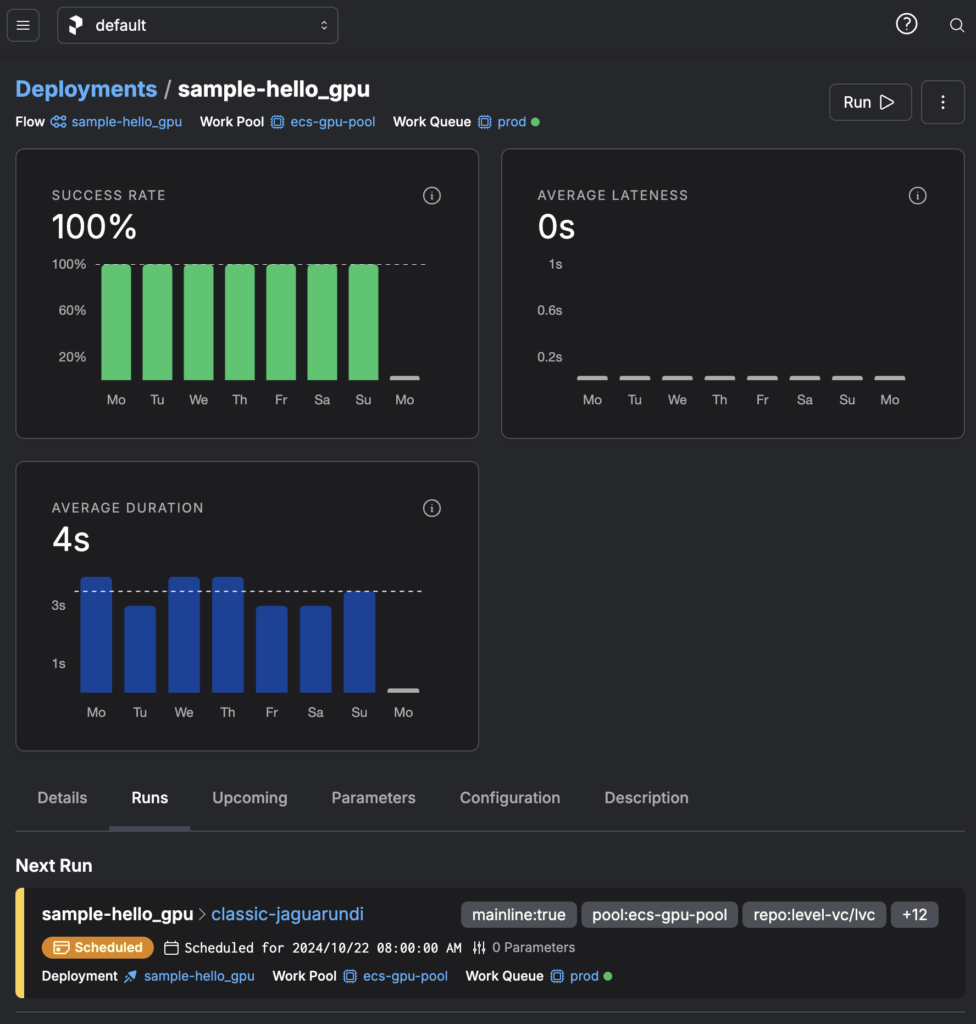
One of the most satisfying things is hitting the “Run” button at the top right corner. (You’ll notice that this flow is also “scheduled” because we have it run daily just to make sure we didn’t break anything.)
Hitting the “Run” button puts several things in motion:
End-to-end, a successful flow run will look this in the Prefect UI:
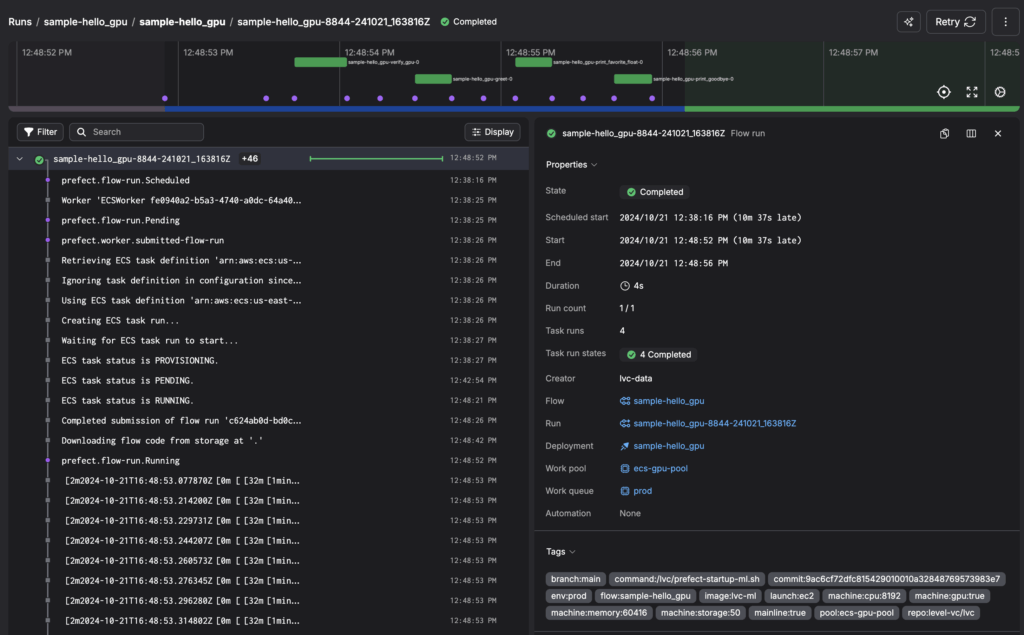
To manage our infrastructure, we use Terraform and the Prefect API. Our framework that sits on top of Prefect handles a variety of niceties, like automatically adding relevant tags to make workflow runs more searchable. We even have special meta workflows that run cleanup tasks and performance checks for our infrastructure. When experimenting, we also automatically deploy development versions of flows on feature branches, which the Prefect UI keeps organized.
From ideation to production, we manage hundreds of workflows. With Prefect, we track them tightly, whether they’re in-flight, taking longer than expected, or fail completely. Prefect’s Python framework also structures our thinking: separating processes into logical flows and tasks has improved our code quality. And finally, we can easily orchestrate compute, from small flows with a fraction of a CPU to those with multiple GPUs.
Big thanks to the always delightful Prefect team and we’re looking forward to many more workflow runs!